215 | How to use Histograms in HP Tuners
Summary
When we’re reflashing a factory ECU we most often can’t make our tuning changes live like we can with an aftermarket standalone ECU. One of the key aspects of being able to tune a factory ECU properly and in a time efficient manner is by using a data logger or scanner software package. In this webinar we’ll look at the histogram feature in the VCM Scanner software and explain how it can be used to help us with multiple tuning tasks.
| 00:00 | - Hey guys it's Andre from High Performance Academy, welcome along to anther one of our webinars and today we're going to be talking about the topic of histograms. |
| 00:09 | Specifically we're going to be looking at how we can use the histogram functions in the HP Tuners VCM scanner software in order to speed up the process of reflashing vehicles. |
| 00:22 | Now at the end of our webinar as usual, we will be having a question and answer session, so if there's anything that I talk about today in this webinar that you'd like me to elaborate on or anything just generally related to the topic we're discussing, please feel free to ask your questions in the comments, the team will transfer those through to me and we'll deal with those at the end. |
| 00:41 | First of all, I want to get into what is a histogram or more to the point, why we need histograms. |
| 00:47 | And really this comes down to some of the limitations when it comes to reflashing a vehicle as opposed to live tuning using an aftermarket standalone ECU. |
| 00:58 | Now in most instances but certainly not all, when it comes to reflashing we aren't able to make our tuning changes live in real time. |
| 01:08 | Most of the time what we need to do is gather some data, then we need to shut off the engine, analyse that data, decide on what changes need to be made and then apply those changes to the map before reloading that map into the ECU by the process of reflashing. |
| 01:24 | So this on face value can seem like quite a time consuming process. |
| 01:28 | And particularly for those who are coming across from the aftermarket standalone tuning world, particularly given the complexity of a factory ECU, it can seem quite daunting. |
| 01:39 | There's a huge amount of parameters that may need to be adjusted and when we can't make live tuning changes, it can seem on face value that there's absolutely no way we're going to be able to tune the engine properly. |
| 01:51 | Or at best we're going to end up spending absolutely hours and hours on the dyno to get everything fine tuned. |
| 01:59 | So this is where histograms come in. |
| 02:03 | And I'll cover off what is a histogram. |
| 02:05 | So basically it is a 2D or a 3D table that we can develop in the VCM scanner software and it allows us to gather a huge amount of data while the engine is running. |
| 02:16 | We can then process that data and it allows us to very quickly make wholesale changes to a large area of a particular table that we're interested in tuning. |
| 02:26 | This for example may be our mass air flow sensor calibration table, perhaps we're looking at optimising our ignition timing tables, or we could be looking at optimising our speed density tables if we're running a speed density configuration. |
| 02:41 | Really doesn't matter, we've got a lot of flexibility in developing those histograms so that we can scan the correct parameter on the correct axes so that we can use that data to very quickly dial in our tune. |
| 02:55 | This will be used, as you'll see during the demonstration, in conjunction with a function called the paste special function, where we can basically take the output from our histogram and then apply those changes, obviously if they're in the correct format, in terms of a percentage error for example, directly into the table that we then want to adjust. |
| 03:15 | One really important aspect, and I'm going to be sort of diving into this in a bit more detail as we go through the webinar, is that the histograms are a case of if we put garbage into the histogram, we're going to get garbage out. |
| 03:29 | So we need to really understand how to develop the histograms for a start, and we need to understand some of the implications around how we run the car and how we drive the car in order to get some clean data that we can use to rely on and then modify our tables to suit. |
| 03:47 | Alright so what we'll do is we'll jump in and we'll have a quick look at a histogram here, so let's head across to my laptop screen. |
| 03:54 | What we'll do is we'll just get our car up and running and at the moment we're sitting here at idle. |
| 04:01 | So for those who have followed any of our webinars before, you'll have seen me spend quite a lot of time on the chart logger where we're logging individual parameters or PIDs versus time. |
| 04:12 | We can see how those are responding versus time. |
| 04:15 | Useful to a point, particularly if you're looking at the results for example of a single ramp run, we can see at each point through the ramp run, exactly what was happening and we can pinpoint areas that we may need to make modifications. |
| 04:30 | Particularly for example if we've done a single ramp run and we're looking at a parameter such as our knock retard where we've got a little bit of knock activity we can pinpoint where that happened. |
| 04:40 | Likewise of course if we're looking at our measured air fuel ratio, we can see if we're too rich or too lean. |
| 04:46 | That's fine for a ramp run but that doesn't really help us fill in the rest of our tables and particularly for our ignition tables for example, we've got a large three dimensional table, let's just actually head back over and we'll have a quick look at that, we'll head across to our spark tables in our VCM editor. |
| 05:05 | And we're going to be basically making most of our changes here in our base high octane table. |
| 05:12 | I'll open that up and we've got a three dimensional table so we've got our spark or cylinder air mass on our vertical axis and we've got our engine RPM on the horizontal axis. |
| 05:22 | So for example, the ramp run that I just talked about, we might be starting somewhere down here around about 0.64 to 0.68 grams per cylinder, and we might sort of come down to around about 0.8, 0.84 grams per cylinder before dropping back. |
| 05:38 | So what we can see here is particularly during a ramp run, we're really only accessing a very narrow area of this spark table. |
| 05:47 | Doesn't really give us a lot of insight into the rest of those areas, particularly the cruise and the transient areas, and that's where using our histograms can help us. |
| 05:57 | So we'll head back across to our VCM scanner software. |
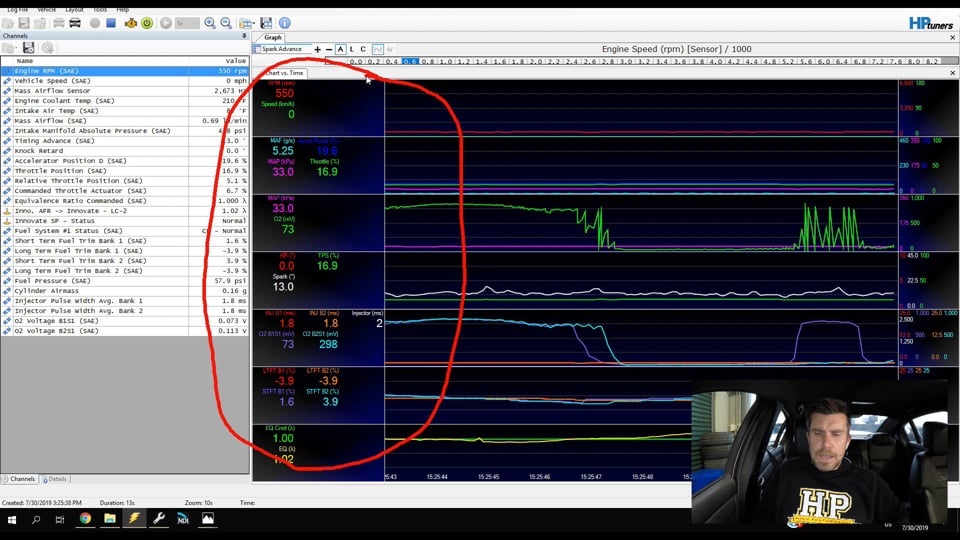
| 06:01 | What we'll do is we'll get our chart logger out of the way for the moment and we'll have a look at our histograms, or graphs as they're called here. |
| 06:08 | So we're going to have a look at a few of these histograms and just see how they're set up. |
| 06:12 | For example here at the moment we are on our spark advance histogram. |
| 06:16 | What we'll do is we'll come down to, actually no we'll stay on our spark advance and we'll just see how we can actually get data. |
| 06:23 | So at the moment we can see we're sitting at idle so it's showing us the current areas we are accessing so you can see basically while the time I've been operating or talking here, we've been at about 0.16 grams per cylinder and we've been moving between about 400 and 600 RPM. |
| 06:40 | So what we'll do is we'll just get ourselves up and running here and just do a little bit of steady state driving. |
| 06:47 | And you can see basically as I change my RPM and my throttle position, we can see that we move into different areas of that table. |
| 06:56 | Just to really highlight this, I'll just stop the scanner and restart it. |
| 06:59 | And so at the moment we're sitting at 1600 RPM using very very light throttle and we can see we're sitting at about 0.2 to 0.24 grams per cylinder. |
| 07:09 | So to fill this table in, what I can do is use a variation on my throttle position and then a variation on our engine RPM. |
| 07:18 | We can do this using our dyno. |
| 07:20 | So for example if I now just gently apply a little bit more throttle, what we're going to see is as the throttle opens, the air flow into the engine increases and we can see that we drop down in that table. |
| 07:30 | It's actually just locked up the torque converter as well so we've seen our RPM change. |
| 07:35 | So what I'll do now is I'll just increase the set point on our dyno and we can see that our RPM increases. |
| 07:41 | So just by moving the throttle, let's give us a little bit more RPM, come up to 1800, and we can move quite accurately around this table or this histogram. |
| 07:51 | So I'll just close that down there. |
| 07:53 | So that's a fairly basic histogram that we've just looked at there. |
| 07:57 | Basically what it's doing is looking at the actual ignition advance angle that's being delivered to the engine. |
| 08:05 | And that's quite valuable thought because while we've got our spark advance tables, our base and our low octane table, high octane and low octane tables, there are also a range of modifiers that will apply corrections to the final spark that is being delivered to the engine. |
| 08:22 | So using this histogram, we can see for a particular operating point in our engine exactly what the timing was that was being delivered to the engine. |
| 08:33 | So one thing I will also mention here, if we head back across to my laptop screen here, we've got the ability to show a couple of points here. |
| 08:42 | At the moment I've got A, which is average values, highlighted. |
| 08:46 | So that will show, as its name implies, the average value of the numbers that have been logged into a particular cell while we've been running. |
| 08:55 | To the left of that we can see we can either show the maximum values or the minimum values. |
| 09:01 | The other one that we will be wanting to look at here, particularly when we are scanning some data is the count, or the number of hits a partcular cell has seen. |
| 09:11 | So if I click on that, what it's showing us here is the number of times data was scanned into a particular cell. |
| 09:18 | So this is important because particularly if we just flash past a cell, we might only get one or two hits of data into that cell, we can't really rely on that data, it's not necessarily going to be particularly valid. |
| 09:32 | So for example here, when I was starting this demonstration, I was sitting for a fairly decent period of time at about 0.24 grams per cylinder. |
| 09:41 | So we can see that we've got 622 hits in that particular cell. |
| 09:45 | On the other hand we can see here as I backed off the throttle, at 1800 RPM and 0.24 grams per cylinder, we only got five hits in that particular cell. |
| 09:55 | So it's important because again this comes down to garbage in, garbage out, if we don't have good solid data, a good decent number of hits in a particular cell to get a valid average, this can be really misleading to our data. |
| 10:09 | So that's a brief look there at our histograms, don't worry we're going to be coming back and having a more thorough look into those shortly. |
| 10:17 | But now that we know what they are, it's probably worth talking about what can they be used for. |
| 10:23 | So essentially we're going to be using these for anything where we really need to be able to gather a reasonably large amount of data to help us tune a table that is going to be difficult if we can't do it live. |
| 10:38 | So a couple of examples of that would be our mass air flow sensor scaling, our mass air flow sensor calibration. |
| 10:46 | Now if we jump back across to our VCM editor software, and we'll close down our spark table here for a moment, we'll go back across to air flow and if we look at our mass air flow calibration, click on that, this is our 2D table of air flow, frequency out of our mass air flow sensor, so this is that input that the engine control module receives, versus our actual air flow in grams per second. |
| 11:11 | So this is really the basis of tuning a factory engine management system that uses a mass air flow sensor. |
| 11:18 | If this isn't correct then everything is going to basically be really difficult for us. |
| 11:23 | So this is one of the first places we come to tune. |
| 11:26 | If we look at it graphically, we can see that we've got a curve that basically has a normal exponential shape to it, it's relatively smooth, which is exactly what we would expect. |
| 11:40 | Now there are a lot of data points in this particular table though. |
| 11:43 | So it can be difficult for us to fill this in if we aren't going to be using the input from a histogram. |
| 11:51 | So again we'll have a look at how we can do that really shortly. |
| 11:54 | Likewise, if you are performing a speed density tune, this is one of the areas where I know a lot of people new to reflashing really do struggle. |
| 12:03 | Where you've removed the mass air flow sensor, you've got a speed density patch applied or maybe using the virtual volumetric efficiency subsystem in the GM ECU. |
| 12:14 | So let's just have a look at what that looks like. |
| 12:16 | If we click on edit and we go to virtual VE, we can see we've got what looks like now a fairly traditional VE table that we'd expect to see in an aftermarket ECU. |
| 12:27 | We've now got manifold absolute pressure on our vertical axis. |
| 12:30 | And we've got engine RPM on our horizontal axis. |
| 12:33 | The numbers in this table are probably not something that most aftermarket ECU tuners would be familiar with. |
| 12:41 | This is GM VE so it doesn't really line up with the numbers we'd normally expect to see when we're talking about VE, probably numbers in the 80% to maybe 110% efficiency range. |
| 12:50 | But the process is exactly the same, in so much as if we double one of the numbers in this table, we're going to end up introducing double the amount of fuel. |
| 12:59 | But of course when we are forced to tune a speed density table like this, with the technique of reflashing, we can't tune each individual cell live so this is really where it becomes very powerful. |
| 13:14 | To be able to drive the car on the dyno or potentially out on the road or the racetrack, gather a huge amount of data using a histogram and we can basically fill in or access a huge number of these cells very very quickly and then apply those changes to the table. |
| 13:30 | The other aspect we can, we've just looked at is ignition timing. |
| 13:34 | Now I looked at ignition timing there which shows us the actual ignition timing being delivered to the engine. |
| 13:41 | However another aspect that really goes hand in hand with that, if we go back to our scanner software here, we've got our spark advance histogram. |
| 13:50 | Directly below that we've got our spark retard histogram. |
| 13:54 | And this is a really powerful way of analysing a huge amount of data. |
| 13:58 | Particularly if you take the car out on the road and you go through a drive cycle, quite often you may end up with some light detonation or knock that's occurring in some of the transient or light throttle areas that are difficult to map on the dyno. |
| 14:12 | And even in this particular graph here, this histogram here, we can see that we do have a really small amount of knock activity that has been logged here. |
| 14:20 | So essentially what this does is it logs any knock retard activity that's occurring and it logs it into the current cell where that knock activity happened. |
| 14:29 | So it makes it really easy when we've gathered a huge amount of data to quickly highlight any areas in the ignition tables that might need some work. |
| 14:38 | And this is pretty minor, I'm not really going to be too worried about this but for example if we're getting maybe knock retard of two to three degrees in this area, maybe if we're under a little bit more load, we can straight away see that we were in the 0.40 to 0.44 grams per cylinder air flow and we were at 1400 to 1600 RPM. |
| 15:01 | So what we can do is head back across to our editor, we'll close down our virtual VE table, go back to our spark high octane table, and we were, in this particular region here. |
| 15:15 | So it allows us to then highlight the particular cells that we were operating in and let's say we might want to take one degree out of that particular set of cells. |
| 15:26 | So it makes it quick rather than trying to individually tune every single cell. |
| 15:32 | There are other areas where we can use histograms as well to our advantage. |
| 15:35 | One would be tuning the base running air flow for our idle speed control for example where we can set up a two dimensional table of our engine coolant temperature versus base running air flow. |
| 15:48 | Start the car and allow it to come up, warm up to operating temperature, and that histogram will then fill in with the air flow numbers which we can then copy, once the table's complete, out into our actual base running air flow tables in our VCM editor. |
| 16:04 | So a really quick way of basically fine tuning a huge number of our parameters. |
| 16:09 | Now I just want to talk a little bit about setting up the ECU. |
| 16:14 | Because I did mention that if we've got garbage data going into one of these tables, we're going to end up getting garbage out the other end and it's not going to help so us we do need to understand a few aspects that will help us get the best quality results. |
| 16:32 | And of course a lot of this comes down to what you're trying to do. |
| 16:35 | So for example, one of the common areas that we would use this is for helping us rescale a mass air flow sensor as we've already talked about. |
| 16:44 | Now if you want to do this and you are using data from a wideband air fuel ratio sensor that's input into the VCM scanner software, one of the keys is that you want to make sure that the engine control module is placed into open loop control mode. |
| 17:00 | So basically if it's running in closed loop, it's going to be taking feedback from the narrowband sensors to correct any error. |
| 17:07 | So of course with our wideband sensor, we're not going to measure any error because the ECU's doing a lot of the heavy lifting in the background, correcting any error that may be there. |
| 17:17 | So we need to place the ECU into open loop mode. |
| 17:20 | Likewise with the GM engine control modules, we have the speed density subsystem, the virtual VE system working in the background. |
| 17:28 | So if we want to focus on just tuning our mass air flow sensor calibration, we want to disable the virtual VE and make sure that the engine control module is forced to only use the mass air flow sensor while we are performing that calibration. |
| 17:44 | The complete reverse is of course accurate there if we are doing the speed density subsystem as well, we need to disable the mass air flow sensor. |
| 17:53 | Otherwise we're not getting a true representation of what the engine control module thinks is occurring. |
| 17:59 | Now I'm not going to go into too much detail on those two aspects there, but if you are interested in learning more, we do cover this in detail in the practical reflash course. |
| 18:10 | There is a worked example that covers the speed density and virtual VE subsystems, and we go through the exact process of disabling and re-enabling those two subsystems to get the best result. |
| 18:21 | The other aspect that's really easy to overlook is how we drive the car when we are gathering this data. |
| 18:28 | And what we want to do is make sure that when we are driving the car, that we don't give any abrupt throttle inputs, this can really easily influence the sort of results we're getting because we'll have transient enrichment coming in. |
| 18:43 | Likewise if the engine is heavily heat soaked, this is going to influence our results. |
| 18:50 | And this is a mistake I see a lot of people make if they are road tuning. |
| 18:53 | What they'll be doing is gathering some data out on the road, then they'll stop on the side of the road, normally they'll leave the engine running, the car, the engine bay will become quite heavily heat soaked, maybe they'll make some changes, flash that into the ECU, then start the car up again and drive off. |
| 19:10 | Now the problem is that for the next few minutes, you're going to find that the heat soak in the engine bay is going to actually impact on the engine's operation. |
| 19:18 | And this is going to give you some results that might not be quite entirely accurate. |
| 19:23 | So it's always a good idea, if you are road tuning in particular, before you start gathering data, to drive the car for a few minutes, monitor your intake air temperature, monitor your engine coolant temperature, and allow those to get down to normal operating values before you actually start gathering data. |
| 19:42 | That's going to give you the best chance possible of getting good results. |
| 19:46 | The other aspect, which we're going to demonstrate a couple of these here, is when we are gathering data, we want to be a little bit sensible and look for any outliers in the data that we're getting. |
| 19:59 | And if we're seeing a fairly consistent trend in the data then all of a sudden, we've got a big jump and then we're back to our normal trend of data, that's probably going to indicate that something might not be right there and we might want to go back and revisit that. |
| 20:15 | So what we'll do, we'll head across to our scanner and let's have a look at the process of gathering some data to optimise our mass air flow sensor. |
| 20:26 | So for a start, let's just have a look, we're going to be using our EQ error MAF table here, our histogram. |
| 20:35 | And let's just have a quick look, we'll right click and we're going to go into graphs layout and I just want to go down to our EQ error MAF graph and see how that's set up. |
| 20:46 | Don't worry too much because we're actually going to create one of these from scratch really shortly. |
| 20:50 | So I'll click on that, and what we've got is our label here. |
| 20:53 | So this is just a name for that particular histogram. |
| 20:56 | I've called it EQ error equivalence ratio error MAF. |
| 21:00 | So just a name that I understand. |
| 21:02 | This is going to log in the parameter equivalence ratio error so that I can help use that to calibrate my mass air flow sensor table. |
| 21:12 | So parameter, this is the next thing that's important. |
| 21:14 | So this is the actual parameter that is going to be logged into our histogram. |
| 21:19 | So this is the value that's going to populate our histogram. |
| 21:22 | And we can change this by clicking on it, not going to at the moment, again we'll see how this works shortly. |
| 21:28 | But the parameter that I've chosen there is a built in MAF channel called the equivalence ratio or EQ error. |
| 21:34 | And in real rough terms, all this does is it looks at the commanded equivalence ratio or commanded lambda value and then looks at the measured lambda value from our wideband and basically creates an error as a percentage, and that's what's going to fill in our table. |
| 21:49 | We can see that the unit there is of course percent. |
| 21:52 | And we are logging this to two decimal places just so we've got a little bit of precision in this. |
| 22:00 | Moving down, I also like to add some shading or colouring to the values and this is just helpful when you're sitting on the dyno or even out on the road or the racetrack because at a glance you can see the colour of the particular values that are being logged, you can see what is predominantly filling up our histogram. |
| 22:19 | And for example here, you've got a high value of ten. |
| 22:23 | So what that would mean is that we've got a 10% error where the air fuel ratio is leaner than our target. |
| 22:31 | So obviously that can potentially be a little bit dangerous, so I've coloured that red just to give me a little bit of a warning. |
| 22:37 | On the other hand, if our air fuel ratio is richer than our target, we've got a green colour with a value of minus 10, you can adjust these to suit your own personal preferences. |
| 22:48 | Now this is the bit where it gets quite powerful. |
| 22:51 | We can see here we've got the ability to choose a parameter for our column axis. |
| 22:57 | So in this case, this is only a two dimensional table, otherwise below that we've got the ability to set up a row axis as well, again you'll see that in action really shortly. |
| 23:07 | So of course what we want to do is choose the same parameter as the table that we're filling in, let's head back across to our VCM editor. |
| 23:15 | We'll go back to our air flow and we want to again click on our MAF calibration. |
| 23:19 | So we can see that the input to the ECU here that we need to help us calibrate this table is mass air flow frequency in hertz. |
| 23:28 | We'll head back across to our scanner and you can see that's exactly what we've got here, mass air flow sensor frequuency and that is in hertz. |
| 23:38 | And then just to really be helpful, what we can also do is select the values, so that's what we've got here, all of these numbers that are separated by a space and those are the same break points as our table. |
| 23:51 | So what this means is for example here, we can see that we've got a break point here at 2100 hertz and if we head back across to our editor we can see that we've got exactly that same break point. |
| 24:03 | So the break points match, and why that's important is that then we can apply the error directly from our histogram straight into this table. |
| 24:13 | So makes it really really quick and easy. |
| 24:15 | Alright so let's get ourselves up and running here and we'll actually have a look at gathering some data here. |
| 24:20 | So I'll just get us running. |
| 24:23 | And what I'm basically doing is starting by using really light throttle input here, and we'll just move across a little bit so we're in the middle of the screen. |
| 24:32 | So we can see that at the moment we're operating at about 4000, 4200 hertz. |
| 24:37 | We can see that the numbers in this here are really close to zero. |
| 24:42 | And you might be thinking that that's because I've done an amazing job with the calibration but just to be completely open here because we're just doing this as a quick demonstration, I'll just point out we can see that our short term and long term fuel trims are still active. |
| 24:59 | So I'm cheating a little bit here, doesn't matter, I'm just really showing you the premise of the system but it is important to understand here that if we really wanted to get data here that was going to be useful to us, of course we would need to disable those short term and long term fuel trims. |
| 25:14 | So we were actually seeing the true error. |
| 25:17 | Alright so what we're trying to do when we are gathering data in this way is we want to be really smooth with our throttle input as I mentioned and what we want to do is start from basically as low down in the frequency as we can get. |
| 25:30 | So I've gone into fourth gear here and I'll just close down the throttle a little bit, we can get down to about 3500 hertz. |
| 25:39 | And you can see here we actually have got a little bit of error but what we want to do when we're accessing any of these cells, is we want to stay in this cell until the number in the cell is relatively consistent. |
| 25:51 | And particularly when you're just starting out and there might be some quite big errors, you're going to find that when you first move into a new cell, there might initially be quite a few seconds that it takes for the number in that cell to sort of even out. |
| 26:05 | So that's really important, again comes down to if you're just flashing through a cell and it's not getting enough time to really get a good number of hits in that cell, you're not going to get good data. |
| 26:14 | So come down to 3500 hertz or so there, so what I'm going to do now is just use a combination of increasing my throttle position and then also increasing the set point on the dyno to allow engine speed to increase and we're just smoothly moving through here, increasing our mass air flow sensor frequency. |
| 26:35 | So we've just stepped up to 4500 hertz there. |
| 26:39 | And you can see as I moved into that cell the number moved around a little bit. |
| 26:42 | It's equalised pretty well there at about 0.9 to 1%, so we'll move up to 4650 hertz. |
| 26:49 | Again I'm just allowing the number to stabilise. |
| 26:52 | And so on and so forth, we're just going to keep stepping up through these cells, allowing each one individually to stabilise. |
| 27:01 | So the other point that's worth making there is particularly when you are using histograms to calibrate your mass air flow sensor, in the GM engine control module, we've got two modes of operation, we've got closed loop and then we've got power enrichment. |
| 27:22 | So power enrichment is when essentially the driver is commanding maximum power from the engine. |
| 27:27 | And we change our target air fuel ratio. |
| 27:29 | So in closed loop mode, which is where we are running right now, the air fuel ratio target is always going to be 14.7:1 or lambda one. |
| 27:37 | We can confirm that just by pulling our graph up here. |
| 27:41 | We can see down the bottom we've got our commanded lambda, lambda one, we've got our measured lambda in yellow there, and you can see that's tracking quite nicely on our target. |
| 27:50 | However what we're going to find is that as we go past our power enrichment throttle setting, we're going to change our air fuel ratio target to whatever we've got in our power enrichment table. |
| 28:04 | So we're just going to do that, we'll just come up here, happens somewhere around about 6500, 7000 hertz. |
| 28:09 | So we'll just get this data because I want to show you what happens. |
| 28:15 | Still in closed loop mode. |
| 28:19 | Somewhere it'll change, OK, alright I'm just going to stop that and we're going to back off and have a look at our results. |
| 28:26 | OK so first of all I'll just bring our graphs up here. |
| 28:30 | And we can see if we look at our air fuel ratio target or commanded lambda versus measured lambda, we can see the point where we transition from closed loop to power enrichment. |
| 28:42 | So closed loop there, we're at lambda one, as soon as we go into power enrichment our lambda target changes from lambda one, in this case to 0.85. |
| 28:49 | And this is a case of what I really want you to watch out for in terms of garbage in garbage out. |
| 28:55 | The engine control module instantly changes that lambda target from lambda one to 0.85 and of course the engine can't track that, the fuelling will change but there's going to be some delay, some latency in actually getting onto that target, which is exactly what we can see has happened here. |
| 29:12 | We can see that our yellow measured air fuel ratio trace takes a couple of tenths of a second to actually follow and get onto our new target. |
| 29:21 | So of course during this period here where we first transition into power enrichment, we're going to end up with a lean error because our measured air fuel ratio is simply leaner than our target. |
| 29:33 | Now that's not very real though and it doesn't actually matter to us. |
| 29:36 | And what that can do is actually influence our results if we don't notice that. |
| 29:41 | So we can see in that particular cell that I've just highlighted there, 7000 hertz, you can see that currently it's showing an error of 3%. |
| 29:49 | That's actually not too bad. |
| 29:51 | Often it can be 10% or 12% instantaneously. |
| 29:54 | But that can really throw us because if we'd stayed there at 7000 hertz, what we would have found is that the number would have then equalised out. |
| 30:02 | We've probably come back to right on our target because as we saw there, everything actually tracked really nicely. |
| 30:08 | So long story short here, particularly when I am using the scanner, the histograms, to fill in our mass air flow sensor calibration, I generally do it in two ways. |
| 30:19 | I'll do some steady state tuning where I'm filling in as much of the low frequency area of this table as I can access before we transition into power enrichment. |
| 30:28 | And I'll use that data and apply that to our table and then once I've done that, I'll also do some ramp runs where we are operating fully in power enrichment and I'll use that data to fill in the higher frequency ranges. |
| 30:42 | So that's important to understand. |
| 30:44 | So coming back to this data though, let's have a quick look at what we've got here, because there are a few aspects that we do need to consider. |
| 30:51 | So first of all let's go back and we'll have a look at our count and we'll see how many hits we had. |
| 30:58 | So we can see for example where I was talking quite a lot at a stationary throttle, we can see that we've got about 2200 hits. |
| 31:05 | We know we've got anything near that sort of number, we can be pretty comfortable that the data's going to be solid. |
| 31:12 | Generally I like to see somewhere around about 200 hits or 200 counts in a particular cell to really rely on the data. |
| 31:18 | Up here at 7000 where I quickly shut down our scanner, we can see that we've only got 26 hits. |
| 31:25 | So again just shows you there, that data I would not be too confident in relying on it. |
| 31:30 | Again we've got a few stragglers here that only got a few hits as well. |
| 31:34 | So particularly, if we go back to the average number, particularly if you've got a number in one of these cells that doesn't really follow, and again because I'm using closed loop, there isn't a huge amount of variation here but for example we see here that 4650 and 4800 hertz, we've got about 0.95, 0.97, then we've got this particular cell here, 4950 hertz, I drop down to 0.29. |
| 32:01 | And then we actually come back up. |
| 32:03 | Now these numbers, I honestly wouldn't be worried about but if we're seeing a more exaggerated change from one cell to the next, maybe we were seeing numbers of 2% and 3%, all of a sudden we've got one single cell at -7% and then in the next cell adjacent we're back to 2% to 3%. |
| 32:21 | That for me straight away is an alarm bell, I'm going to come back and revisit that cell, see if there's something that I did funny around that cell that's actually influenced and got us those results. |
| 32:31 | So it's not a case of just gathering the data and blindly applying it. |
| 32:34 | What we really need to do is have a look at the data, analyse it and make sure that it all makes sense. |
| 32:41 | Now the other aspect here is obviously we weren't able to gather any data below about 3500 hertz here. |
| 32:50 | We can gather some data at idle but what we want to do here is again apply a little bit of common sense. |
| 32:56 | What we're looking for is trends in our data so that we can apply that down in these lower areas that we weren't able to get to, so down below 3500 hertz. |
| 33:05 | What I'm going to basically be doing is looking for trends that I can apply and extrapolate out. |
| 33:10 | And of course there may be individual cells that you aren't able to access and you can't get access to so that's how you're going to need to do that as well. |
| 33:20 | So once you've gathered your data, what can you do with it? How can you use the data? Well there's a couple of ways. |
| 33:26 | One is to manually make adjustments based on the data that you've got. |
| 33:30 | Particularly if you've got really poor quality data with a lot of outliers or numbers that really don't make sense, I'd be very cautious about automatically using that data and instead I would manually use it and I would smooth it out. |
| 33:46 | So how I mean we're going to do this, for example here in our data let's look at from 4350 hertz to 4800 hertz, we are around about, let's call it 1% too lean. |
| 34:02 | So what we could do is take that data, 4350 to 4800, we'll find those same cells, so 4350 to 4800. |
| 34:13 | So what we can do then is highlight those cells here and all we want to do is simply multiply this by 1.01 which adds 1%. |
| 34:21 | So that will basically allow us to look for trends and manually apply them into our mass air flow sensor calibration table. |
| 34:30 | Now particularly if you've got data, as I've said, with a lot of outliers, then that's definitely the way you're going to want to do this. |
| 34:37 | This data however, other than our little error at 7000 which we purposefully included, we've actually got some pretty solid data there, it all looks quite good. |
| 34:46 | Of course it should because we are running in closed loop mode. |
| 34:49 | So what we can do here is highlight that entire table, right click and what we want to do is select copy. |
| 34:56 | Now if we head back across to our editor, what we can do now is right click, and if we come down we'll find this paste special function. |
| 35:04 | So this allows us to apply the error straight into our table. |
| 35:09 | So for example if we come down here to multiply by percent, it's basically going to do exactly what I just did manually, it's going to apply that percentage error, in the case we just looked at I applied a 1% error. |
| 35:22 | This of course is going to apply exactly what's in the data. |
| 35:25 | So we'll do that now, and we can see the areas that have been adjusted there. |
| 35:31 | So that applies that particular error into our table. |
| 35:35 | Now the problem with doing this is of course if we don't have good solid data, this is going to end up potentially causing us a problem. |
| 35:43 | And the other aspect as well is it's not going to make any changes in the areas that we didn't scan data. |
| 35:50 | So if you're going to use the paste special function, you do need to usually do a little bit of hand blending. |
| 35:56 | For example make adjustments to the lower frequency areas where we didn't gather any data. |
| 36:02 | So particularly for your first round of modifications when your mass air flow sensor calibration is potentially a long way out, it's a good idea to use the multiply by percent. |
| 36:12 | Sometimes we can find, because this is an iterative process, sometimes we can find as we make further adjustments, as we get closer, using the multiply by percent can sometimes end up going a little bit too far. |
| 36:23 | So often we are better, once we've made our first round of modifications, using the multiply by 0.5%. |
| 36:30 | So basically it just makes exactly what you'd think there, a smaller change of half of the error and applies that into the mass air flow sensor calibration. |
| 36:38 | Alright I think we've talked about how we apply those changes. |
| 36:42 | Of course if you are making changes into maybe an ignition table, maybe a speed density table, whatever, you are going to be able to do exactly the same thing. |
| 36:53 | Either make those changes manually or apply that paste special functionality. |
| 36:58 | We're going to go into a quick demonstration now of how we can actually set up a custom histogram. |
| 37:06 | And we'll then go into some questions and answers so this is just a good time to remind you, if you do have any questions, please ask those in the comments and we'll deal with those shortly. |
| 37:17 | So what we're going to do is just pretend we're setting up a speed density table and we're going to see how we can set up a histogram that's going to help us with tuning that speed density table. |
| 37:30 | So we'll head back across to our scanner, we're going to right click and we're going to click graphs layout. |
| 37:37 | So what we're going to want to do here is start up or set up a new graph. |
| 37:41 | So we'll use the add graph icon there. |
| 37:44 | We'll click on that, and now we've got a new table which we can see has been added down the bottom here. |
| 37:50 | So we can give that a name, let's say EQ, EQ error SD for speed density. |
| 38:02 | Now we need to click on the parameter that we want to fill in there. |
| 38:06 | So we'll click on that. |
| 38:08 | There's a few ways we can negotiate through or navigate through this list of parameters that we've got available. |
| 38:15 | We can scroll down and select what we want or we can simply start typing and the available parameters will fill in automatically. |
| 38:27 | And in this case what we're actually wanting to do is go down to our maths channels and we're going to use our maths for lambda and air fuel ratio. |
| 38:36 | And we want to use our EQ ratio error. |
| 38:39 | So again that's just that math channel, that gives us the difference between our measured air fuel ratio and our target. |
| 38:45 | Of course we're going to fill that out to two decimal places as well. |
| 38:49 | I'm going to basically replicate the shading that I've already shown you. |
| 38:53 | So plus 10 we're going to be red because we know that we are lean. |
| 38:56 | And at minus 10 we're going to be green because it's not ideal but at least we know that we're safe because we're rich. |
| 39:05 | Right so that's set up our new histogram but of course we need to add some axes. |
| 39:11 | And this is where the power of this system comes in. |
| 39:14 | So let's head back across and just for our example here we're going to use our virtual volumetric efficiency system. |
| 39:21 | And we can see we've got our axes of manifold pressure on our vertical axis and we've got engine RPM on our horizontal. |
| 39:29 | So what we can do is right click and let's start with our vertical axis. |
| 39:33 | So our row axes there, what we want to do is copy labels. |
| 39:39 | So we'll come back across to our scanner, and what we want to do for our row axes, I've done it around the wrong way but that's fine. |
| 39:47 | What we want to do is use our manifold pressure as our axes and then we can click on our values, control V and that will copy in those axes. |
| 40:01 | We're then going to do exactly the same, right click and this time we're going to copy our column axes labels, we're going to come back across and we're going to click our parameter, we're going to use engine RPM and we are then going to right click and we can paste those in there. |
| 40:21 | So that's set up our little SD histogram, we'll close that down and we'll be able to see that is now available. |
| 40:30 | So that's actually got that data that we just scanned in before but let's just get ourselves up and running now and we'll scan some more data in. |
| 40:37 | Hopefully I'm going to be able to show you how important it is to be smooth with our throttle inputs. |
| 40:42 | So at the moment we're at idle, I've just pulled the car into gear, and we can see that it's not very dramatic there because we are running again in closed loop and obviously the engine is reasonably well tuned. |
| 40:54 | But we can see as we transition through, we've got these green areas which aren't very realistic. |
| 41:00 | If we come back and we look at our counts, you can see we've only got just a couple of hits in those cells so again we wouldn't want to rely on that data. |
| 41:08 | So what we're going to do here, when we're filling this in, again we've got exactly the same scenario to consider that at a certain manfold pressure we are going to transition from closed loop mode, targeting lambda one to our power enrichment target. |
| 41:22 | So we want to stay again below that for exactly the same reason. |
| 41:25 | But just to demonstrate this we will go through and see what happens. |
| 41:29 | So we're at 2200 RPM now. |
| 41:31 | Another thing that's important here is when we are using the dyno, we'll see our RPM, our actual RPM value there, we want to watch that because particularly with an automatic transmission, we're going to find that as we apply more load, sometimes we're going to get up a little bit more slip in our torque converter and this may require us to change our set point on our dyno just to make sure that we stay in that same column. |
| 41:57 | Actually this one's pretty good, our torque converter isn't slipping and we're staying basically in the middle of that set of cells. |
| 42:05 | And obviously just like tuning an aftermarket standalone engine management system, if we want to get good solid data we want to be as close to the centre of the cells we are tuning as we possibly can. |
| 42:16 | So we'll just keep coming up here until we end up moving into open loop mode. |
| 42:22 | So let's just watch that. |
| 42:31 | And I'm doing this a little bit faster than I normally would but we'll see what happens when we transition into open loop. |
| 42:41 | I've just shut that off and we'll back off again. |
| 42:44 | So we can see again that's happened up around about 92, 93 kPa and we can see again we've got that instantaneous little error there. |
| 42:53 | Just talking about those outliers. |
| 42:55 | So this again the number's aren't dramatic, I honestly wouldn't be worried about this but it does show just because of the colouring, the sort of idea. |
| 43:03 | So we can see here at 52.5 kPa we've got this little glitch which is minus 0.5%, again absolutely nothing to worry about, given the magnitude. |
| 43:14 | But these are the sort of things we're looking for where there's an inconsistency in the trends that we are seeing and likewise here we've jumped up to 1.4%, 1.6% trim as we've gone into our power enrichment due to that error that we've already talked about. |
| 43:29 | Alright we will move into questions. |
| 43:33 | If you do have any questions on this, please ask those and we'll get into them in a second. |
| 43:43 | And it looks like we've got no questions. |
| 43:46 | OK that makes it nice and easy for me. |
| 43:48 | Obviously I explained everything perfectly. |
| 43:51 | Remember for our HPA members if you do have any questions that crop up after this webinar's aired, if you're watching this in our archive, then please feel free to create a discussion topic in our forum and I'll be happy to answer those questions there. |
| 44:04 | It really is an incredibly powerful way of speeding up the tuning process. |
| 44:08 | And analysing a huge amount of data in a very short amount of time. |
| 44:14 | Thanks for joining us everyone, hopefully we'll see you again shortly, cheers. |